Obtaining the datasets
To obtain the SBVPI dataset, please download, fill out, and hand-sign this form, and send it to Matej at matej.vitek@fri.uni-lj.si.
To obtain the MOBIUS dataset, please download, fill out, and hand-sign this form, and send it to Matej at matej.vitek@fri.uni-lj.si. Please also indicate which of the following you require:
- Full dataset (~3.5GB): this includes all the 16,717 RGB images, including the ones without any corresponding segmentation markups. It also contains all the available segmentation markups, saved as multiclass (multi-coloured) masks.
- Segmentation subset (~700MB): this includes the 3,559 RGB images that have corresponding sclera, iris, pupil, and periocular markups. It also contains those markups, saved as multiclass (multi-coloured) masks.
- Sclera subset (~650MB): this contains the same 3,559 RGB images as the Segmentation subset. It only has the corresponding sclera markups, saved as singleclass (black-and-white) masks.
If you use our datasets in your research, please cite our papers:
@article{vitek2025gazenet,
title={GazeNet: A lightweight multitask sclera feature extractor},
author={Vitek, Matej and \v{S}truc, Vitomir and Peer, Peter},
journal={Alexandria Engineering Journal},
volume={112},
pages={661--671},
year={2025},
publisher={Elsevier},
doi="10.1016/j.aej.2024.11.011"
}
@article{vitek2023ipad,
title={IPAD: Iterative Pruning with Activation Deviation for Sclera Biometrics},
author={Vitek, Matej and Bizjak, Matic and Peer, Peter and \v{S}truc, Vitomir},
journal={Journal of King Saud University -- Computer and Information Sciences},
volume={35},
number={8},
pages={101630},
year={2023},
publisher={Elsevier},
doi="10.1016/J.JKSUCI.2023.101630"
}
@article{vitek2023exploring,
title={Exploring Bias in Sclera Segmentation Models: A Group Evaluation Approach},
author={Vitek, Matej and Das, Abhijit and Lucio, Diego Rafael and Zanlorensi, Luiz Antonio and Menotti, David and Khiarak, Jalil Nourmohammadi and Shahpar, Mohsen Akbari and Asgari-Chenaghlu, Meysam and Jaryani, Farhang and Tapia, Juan E. and Valenzuela, Andres and Wang, Caiyong and Wang, Yunlong and He, Zhaofeng and Sun, Zhenan and Boutros, Fadi and Damer, Naser and Grebe, Jonas Henry and Kuijper, Arjan and Raja, Kiran and Gupta, Gourav and Zampoukis, Georgios and Tsochatzidis, Lazaros and Pratikakis, Ioannis and Aruna Kumar, S.V. and Harish, B.S. and Pal, Umapada and Peer, Peter and \v{S}truc, Vitomir},
journal={IEEE Transactions on Information Forensics and Security (TIFS)},
volume={18},
pages={190--205},
year={2023},
doi="10.1109/TIFS.2022.3216468"
}
@article{vitek2020comprehensive,
title={A Comprehensive Investigation into Sclera Biometrics: A Novel Dataset and Performance Study},
author={Vitek, Matej and Rot, Peter and \v{S}truc, Vitomir and Peer, Peter},
journal={Neural Computing \& Applications (NCAA)},
volume={32},
pages={17941--17955},
year={2020},
publisher={Springer},
doi="10.1007/s00521-020-04782-1"
}
@inproceedings{ssbc2020,
title={{SSBC} 2020: Sclera Segmentation Benchmarking Competition in the Mobile Environment},
author={Vitek, Matej and Das, Abhijit and Pourcenoux, Yann and Missler, Alexandre and Paumier, Calvin and Das, Sumanta and De Ghosh, Ishita and Lucio, Diego R. and Zanlorensi Jr., Luiz A. and Menotti, David and Boutros, Fadi and Damer, Naser and Grebe, Jonas Henry and Kuijper, Arjan and Hu, Junxing and He, Yong and Wang, Caiyong and Liu, Hongda and Wang, Yunlong and Sun, Zhenan and Osorio-Roig, Daile and Rathgeb, Christian and Busch, Christoph and Tapia Farias, Juan and Valenzuela, Andres and Zampoukis, Georgios and Tsochatzidis, Lazaros and Pratikakis, Ioannis and Nathan, Sabari and Suganya, R and Mehta, Vineet and Dhall, Abhinav and Raja, Kiran and Gupta, Gourav and Khiarak, Jalil Nourmohammadi and Akbari-Shahper, Mohsen and Jaryani, Farhang and Asgari-Chenaghlu, Meysam and Vyas, Ritesh and Dakshit, Sristi and Dakshit, Sagnik and Peer, Peter and Pal, Umapada and \v{S}truc, Vitomir},
booktitle={IEEE International Joint Conference on Biometrics (IJCB)},
pages={1--10},
year={2020},
month={10},
doi="10.1109/IJCB48548.2020.9304881"
}
@incollection{rot2020deep,
title={Deep Sclera Segmentation and Recognition},
author={Rot, Peter and Vitek, Matej and Grm, Klemen and Emer\v{s}i\v{c}, \v{Z}iga and Peer, Peter and \v{S}truc, Vitomir},
booktitle={Handbook of Vascular Biometrics (HVB)},
editor={Uhl, Andreas and Busch, Christoph and Marcel, S\'{e}bastien and Veldhuis, Raymond N. J.},
pages={395--432},
year={2020},
publisher={Springer},
doi="10.1007/978-3-030-27731-4_13"
}SBVPI
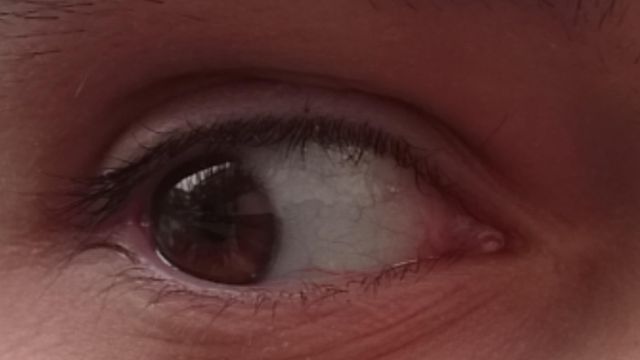
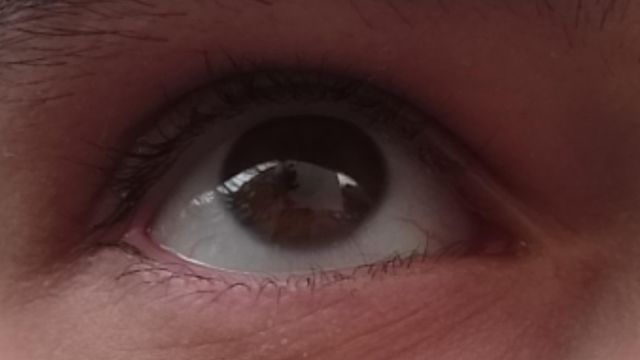
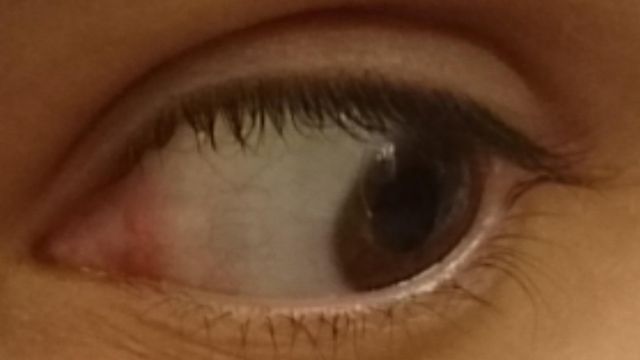
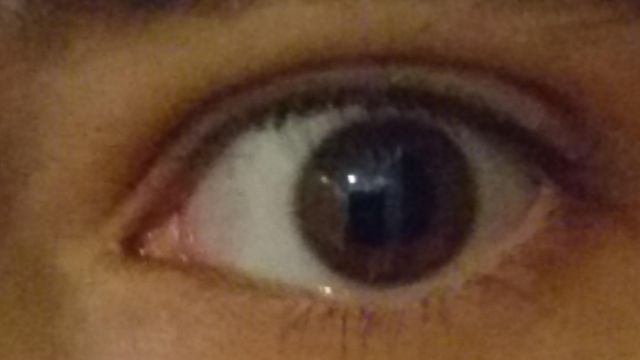
SBVPI (Sclera Blood Vessels, Periocular and Iris) is a publicly available dataset designated primarily for research into sclera recognition, but it is also suitable for experiments with iris and periocular recognition techniques. It consists of 1858 high-resolution RGB images of eyes from 55 subjects. Images of the dataset were captured during a single recording session with a digital single-lens reflex camera (DSLR) (Canon EOS 60D) at the highest resolution and quality setting. Macro lenses were used to ensure sufficiently high-quality and visibility of fine details in the captured images. This procedure resulted in images with clearly visible scleral vasculature patterns, as shown in Figure 1.
The acquisition procedure for the dataset involved the following steps:
- The camera was positioned at a random distance of 20–40 centimetres from the subject's eyes.
- After each acquisition, the camera was moved randomly up/down/left/right by 0–30 centimetres and the subject was asked to very slightly alter his/her eyelid position and view direction.
- The above step was repeated several times to get multiple images of the same subject with the (almost) the same view/gaze direction, since even a very slight change in view direction causes significant changes in the appearance of the scleral vasculature, so our acquisition procedure was devised with development of algorithms robust to such changes in mind.
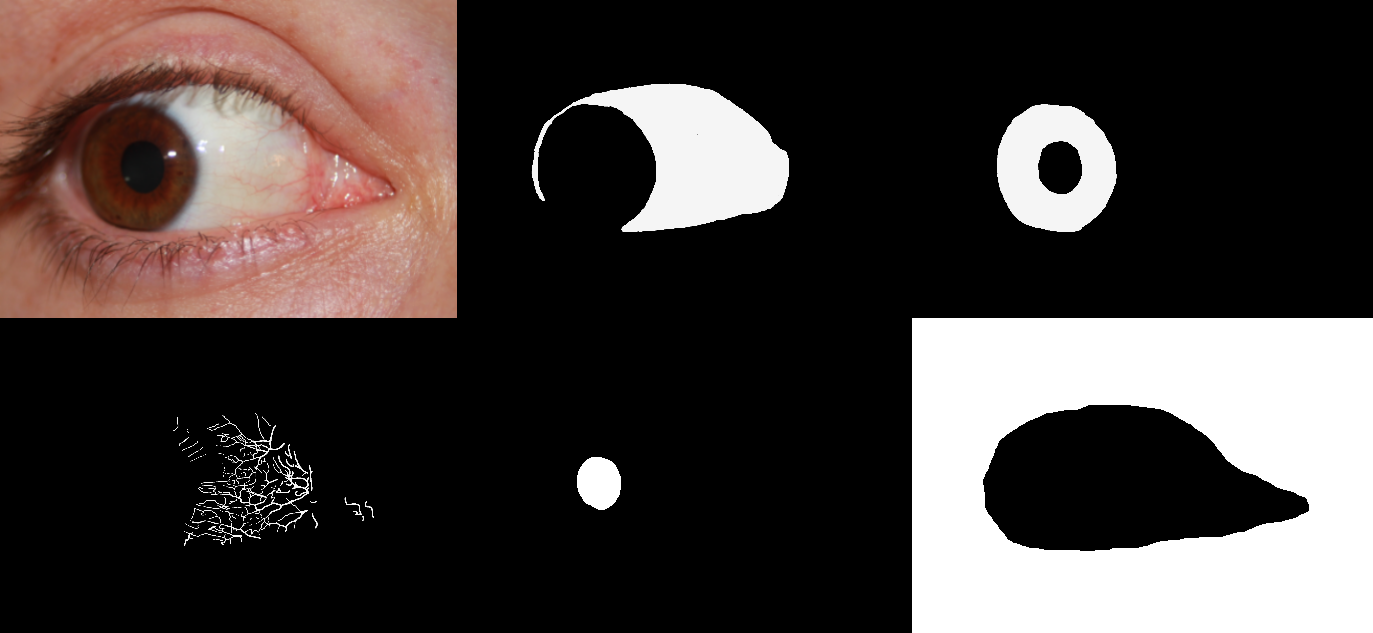
Each sample in the database is labelled with an identity (one of 55), age (15–80), gender (male or female), eye (left or right), gaze direction (left, right, up, straight) and eye colour (brown, green, blue). Additionally, all 1858 images contain a manually-generated pixel-level ground truth markup of the sclera and periocular regions, as illustrated in Figure 3. A subset of 100–130 images (depending on the region) also contains a markup of the scleral vessels, the iris, the canthus, eyelashes, and the pupil. We used the GNU Image Manipulation Program (GIMP) to generate the ground-truth markups, which we included in SBVPI as separate images. Overall, the annotation process alone required roughly 500 man-hours of focused and accurate manual work. To conserve space, we later converted the markups into binary mask images, which (using lossless PNG compression) reduced the size of the entire dataset by a factor of approximately 6×. These masks are included in the final publicly available version of the dataset.
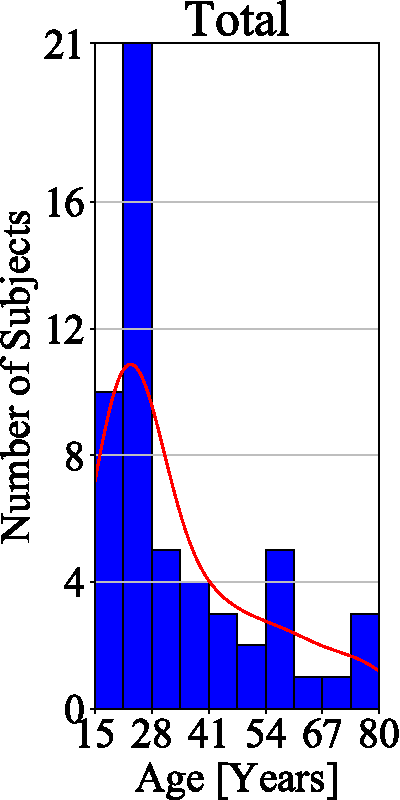
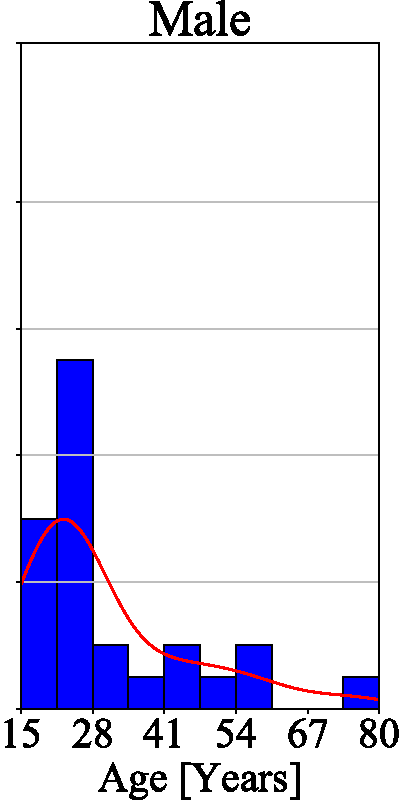
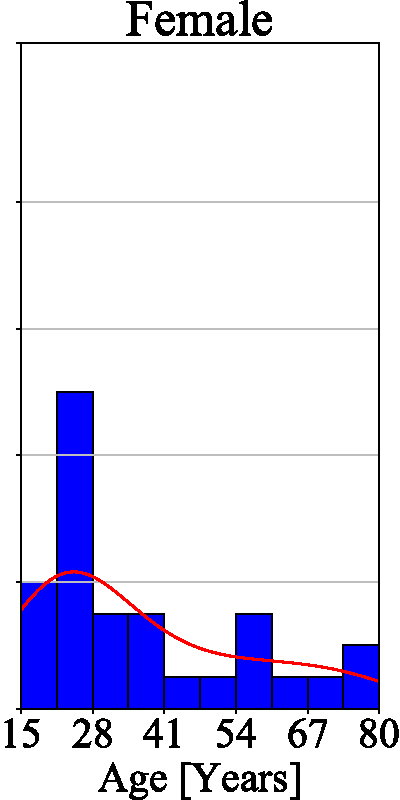
The final dataset contains images of 29 female and 26 male subjects and is therefore (approximately) gender balanced. All the subjects in the database are of Caucasian origin, with ages ranging from 15 to 80. The majority of our subjects are under 35 years of age, as evidenced by the age histogram on the left of Figure 4. There is no significant deviation between the age distributions of male and female subjects — see the two histograms on the right of Figure 4. SBVPI also contains eyes of different colours, which represents another source of variability in the dataset.
MOBIUS
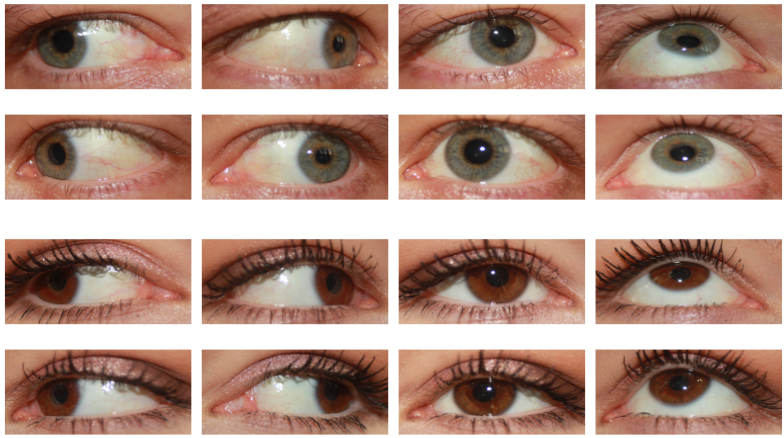
MOBIUS (Mobile Ocular Biometrics In Unconstrained Settings) is a publicly available dataset primarily intended for mobile ocular recognition research. It was developed at the University of Ljubljana in 2019. It consists of 16,717 RGB images collected from 100 subjects. The images are high-resolution and were captured with the cameras of 3 different commercial mobile phones — Sony Xperia Z5 Compact, Apple iPhone 6s, and Xiaomi Pocophone F1.
To acquire the images we followed the procedure outlined below:
- The phone was positioned as close as possible to the subject's eye while still keeping the image sharp.
- The subject then took a set of 4 photos, one per each view direction — left, right, up, and straight ahead.
- The previous step was then repeated (this was done to keep a bit of variability in gaze even with the same view direction).
- The images were manually inspected for quality and re-taken if necessary.
We additionally captured one bad image per view direction per eye in a randomly chosen lighting for each subject, using motion blur, occlusions, excessive specular reflection, etc. Our dataset thus also contains 24 bad images per subject (3 phones × 2 eyes × 4 view directions), intended for the development automatic quality control methods. This gives us a combined 168 images per subject. We show some samples from the dataset that demonstrate the various image qualities and gaze directions present in the dataset in Figure 1. In total, the collection process required roughly 100 man-hours of work.
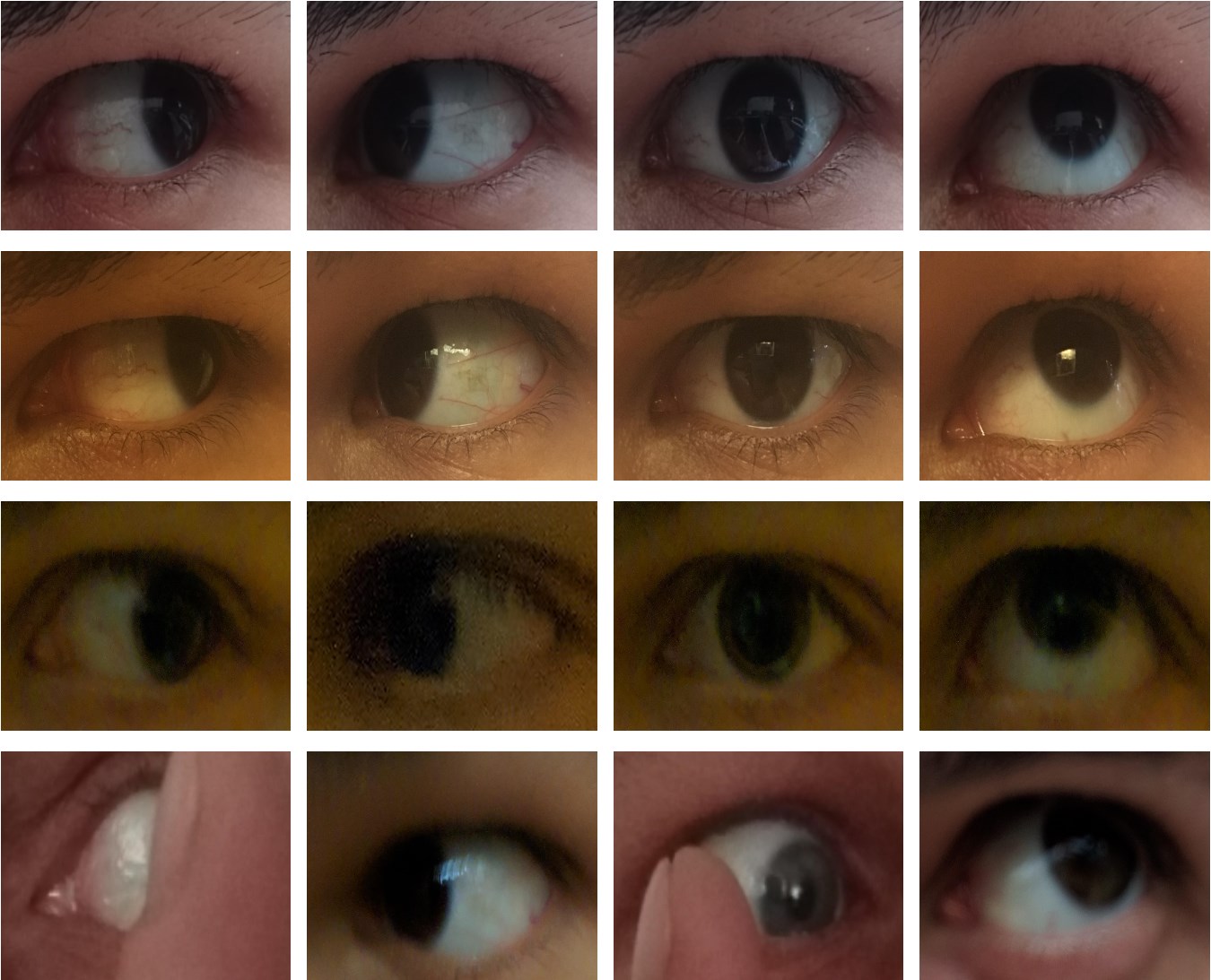
Despite our best efforts to contain the camera's receptive field to the eye while capturing images, a significant part of the images was still extraneous information — nose, mouth, eyebrows, etc. Since our dataset focuses on ocular studies, we used a semi-automated cropping procedure to extract the desired regions of interest (ROIs), keeping only the eye and a small part of the periocular region. We additionally rescaled the images to a uniform size of 3000×1700, using bicubic interpolation.
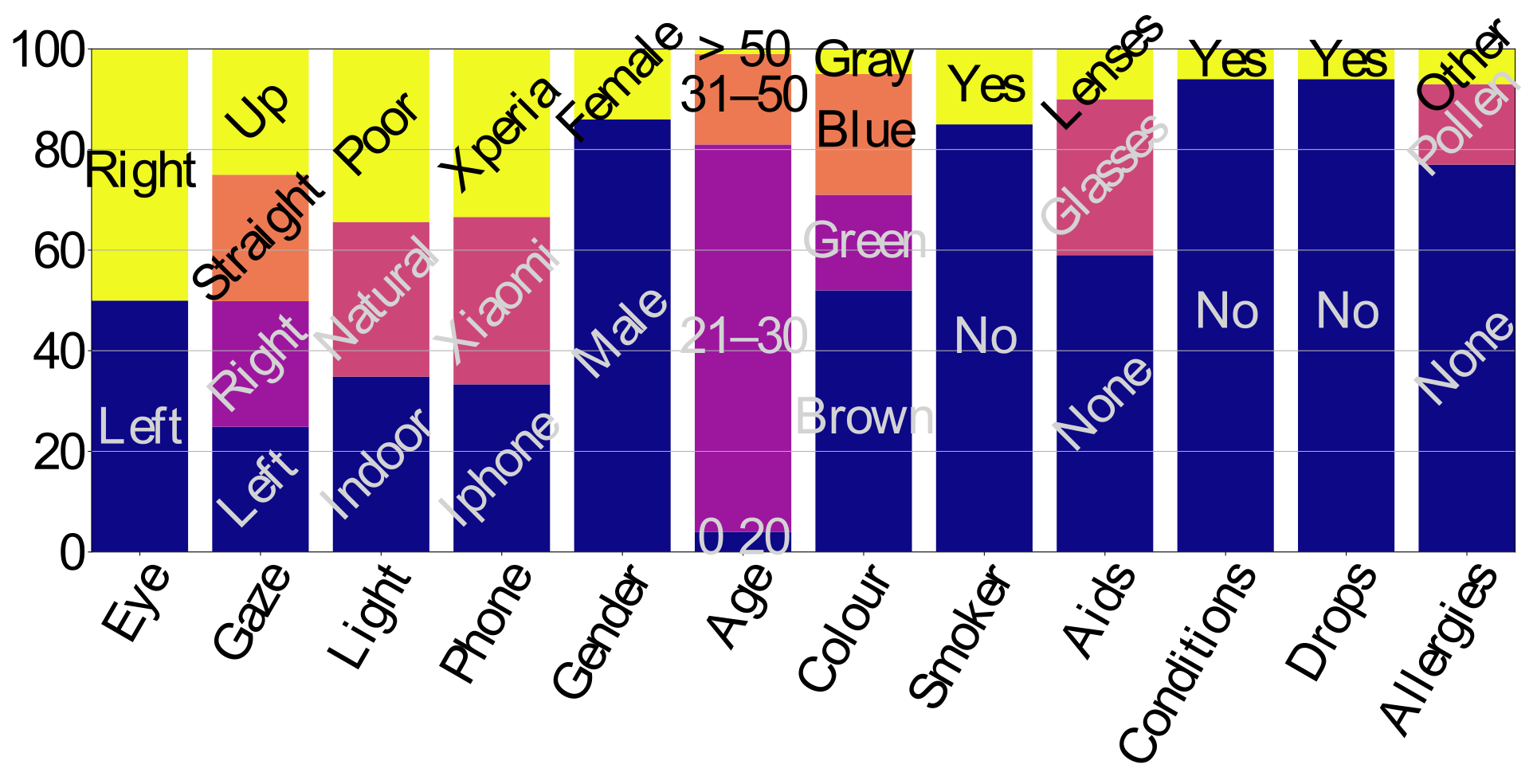
The dataset comes bundled with an info sheet file that contains detailed information about the individuals in the dataset. Namely, for each subject we have information about their gender, age, eye colour, vision aids (glasses, lenses) and their strength (dioptres, cylinders), whether they smoke, whether they have any eye conditions or allergies, and whether they used any eye drops prior to the image capturing. Figure 2 shows the distributions of the subjects in the dataset, relative to each of these personal traits. The images themselves are also labelled with the subject identity, capturing conditions (phone, lighting), eye (left/right), gaze (left, right, straight, up), and number in the set. For more information on the image labels see the bundled README file.
Segmentation subset
A subset of 3559 images also comes with manually crafted markups of the sclera, pupil, iris and periocular regions, as can be seen in Figure 3. The markups were created by first running a CNN-based multi-class segmentation model (trained on the SBVPI dataset) on the images, and then hand-correcting the masks given by the model, using a plugin for the GNU Image Manipulation Program (GIMP) custom-made for this purpose by Matej Vitek. At 5–10 minutes per image, the annotation process required roughly 500 man-hours of manual work. Afterwards the annotations were corrected using a semi-automated procedure to remove certain artifacts, noise, and other distortions in the images. This is explained in more detail in our paper Semi-automated correction of MOBIUS eye region annotations.